
Goal
Client wanted to continuously quantify how the biggest and 200+ most polluting companies compare to each other (on the 0-100 scale) when it comes to their reputation + performance in causing less pollution + pro-activity in the space of general sustainability.
Role
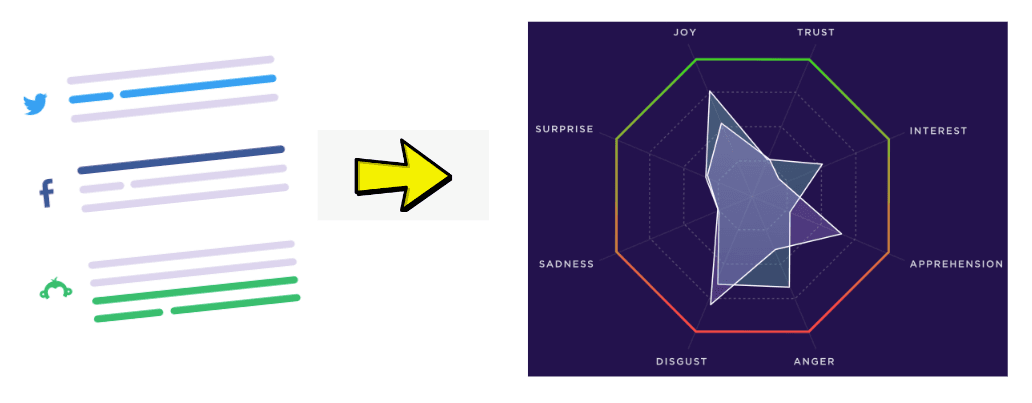
- Leveraged python OOP code across various tasks, reducing time-to-delivery by 60%. The code executes competitive benchmarking and sentiment analysis, thus improving the client’s campaign accuracy.
- Co-developed python data pipelines for web crawling, ETL, data validation, and testing. To our client this serves as an extensive and efficient social listening system. The system scans corporate social media, annual reports for the 200+ companies, processes the data and feeds into the charts and KPIs at the front-end.
- Quantified the reputation, sustainability and pollution reduction efforts across 200 target companies. Outcome was key in the acquisition of 2 new high-profile clients;
Capability
Multi-source and multi-keyword data pipelines driving sentiment analysis, competitive benchmarking and effective resource allocation in multinational advertising and public relations company.
Tech Stack
Python (OOP) ; PyTest ; data pipelines building (Python + Luigi) ; Regular Expressions (Regex) ; Git ; Data validation (Great Expectations); Data ETL ; Web crawling (pages and apis) ; AWS S3
Year
2022