Goal
Empower businesses to ensure privacy compliance by seamlessly capturing, documenting, and preserving proof of cookie consent in line with the latest data protection regulations and integrating with industry initiatives like Google Consent Mode v2.
Role
As the lead developer, I designed, implemented and deployed a robust, scalable solution for capturing and managing cookie consent. My role spanned end-to-end system architecture, backend development, and seamless integration with front-end interfaces to deliver a compliance-ready system tailored for modern privacy standards.
- Solution architecture. Designed and implemented a scalable pipeline leveraging Redis for real-time data capture and MySQL for long-term consent storage, ensuring fast, reliable processing across high-traffic environments.
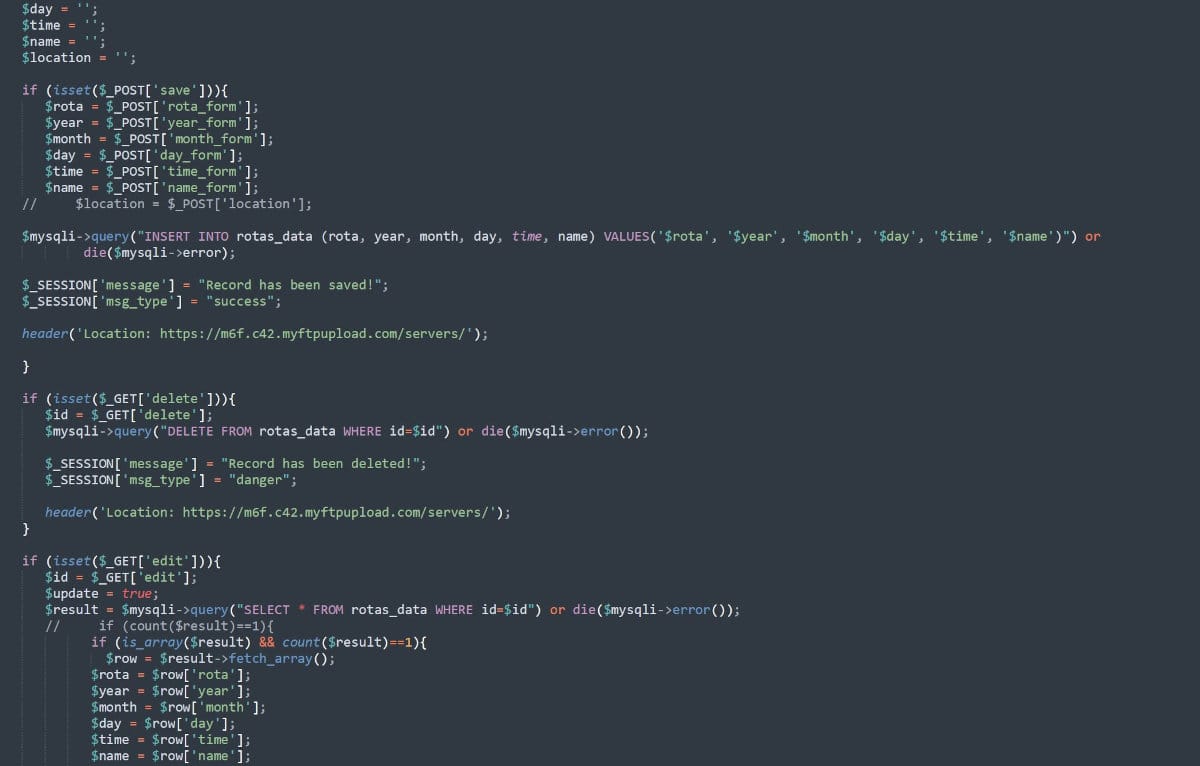
- Front-end and backend integration. Combined JavaScript and PHP to enable real-time synchronization between cookie banners and server-side logging, delivering a secure and seamless user experience.
- Automated data workflows. Built cron jobs to move data from Redis to MySQL, ensuring data retention policies align with compliance requirements while enabling detailed reporting.
- Privacy compliance enablement. Integrated with Google Consent Mode v2, ensuring the system supports the latest privacy regulations and puts user control at the forefront.
- Custom logging and validation. Developed robust backend logic for consent data validation, rate limiting, and intent analysis, ensuring data accuracy and regulatory compliance.
Capability
This solution acts as an intelligent, automated system for capturing and managing cookie consent data, ensuring compliance with modern privacy regulations while maintaining a seamless user experience for website visitors.
- Consent Data Capture: Tracks user consent actions—both explicit and implicit—by integrating seamlessly with your website’s cookie banner. This ensures every interaction is logged securely and accurately.
- Speed and Reliability: A robust combination of fast in-memory processing (Redis), rate limiting, and PHP validation ensures high performance, even during traffic spikes.
- Data Synchronization Pipeline: Smart orchestration of cron jobs moves consent data from Redis to MySQL, ensuring long-term storage and compliance tracking, enabling detailed reporting and reducing reliance on third-party cookies.
- User Control & Privacy Regulation Compliance: Full compliance with privacy standards like Google Consent Mode v2 allows users to control their data while giving businesses confidence in their ability to meet GDPR and other privacy requirements.
- Customizable and Scalable Design: Built to adapt to your specific needs with configurable cookie expiration policies, ensuring it grows with your business while remaining fast and efficient.
Tech Stack
- Consent Management & Privacy Logic: Google Consent Mode v2, WordPress Cookie Plugin
- Front-End Integration: JavaScript, jQuery
- Real-Time Data Processing: Redis, PHP
- Server-Side Validation & Logging: PHP, Predis (Redis Client)
- Data Storage & Synchronization: MySQL, Cron Jobs
- API Communication & Debugging: jQuery AJAX, Custom API Endpoints
Year
2024